什么是K8s
k8s解决的问题
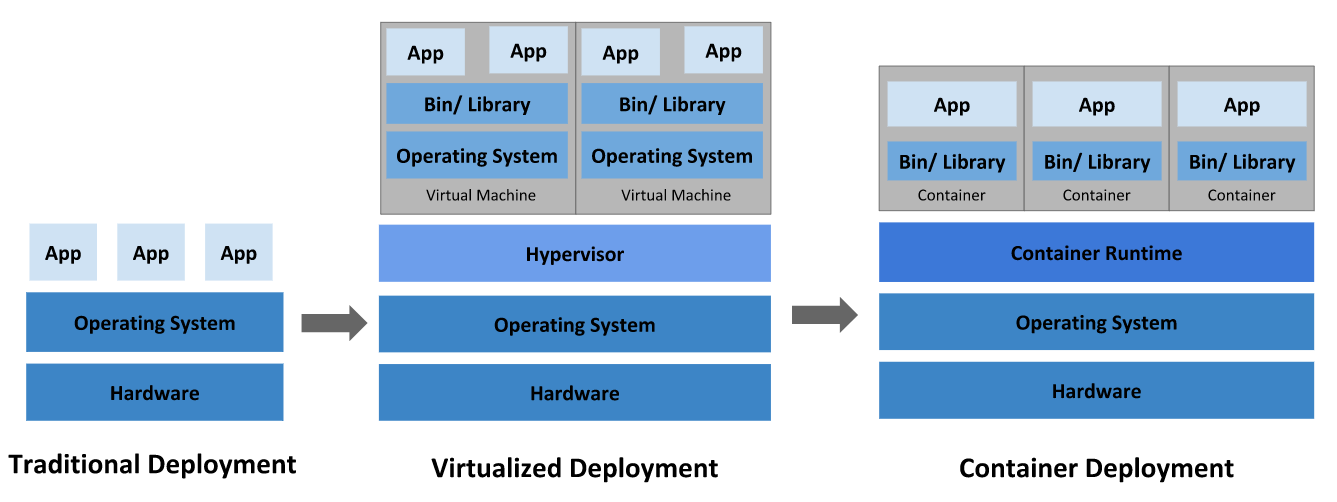
让我们回顾一下为什么 Kubernetes 如此有用。
传统部署时代:
早期,各个组织机构在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。
例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况, 结果可能导致其他应用程序的性能下降。
虚拟化部署时代:
作为解决方案,引入了虚拟化。虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)。
容器部署时代:
容器类似于 VM,但是它们具有被放宽的隔离属性,可以在应用程序之间共享操作系统(OS)。 因此,容器被认为是轻量级的。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。
解决的问题
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。z
K8s的特点
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果进入容器的流量很大, Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。
存储编排
Kubernetes 允许你自动挂载你选择的存储系统,例如本地存储、公共云提供商等。
自动部署和回滚
你可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态 更改为期望状态。例如,你可以自动化 Kubernetes 来为你的部署创建新容器, 删除现有容器并将它们的所有资源用于新容器。
自动完成装箱计算
Kubernetes 允许你指定每个容器所需 CPU 和内存(RAM)。 当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。
自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的 运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。
密钥与配置管理
Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
Main Components
左侧是一个官方提供的名为 kubectl 的 CLI (Command Line Interface)工具,用于使用 K8S 开放的 API 来管理集群和操作对象等。
Master 是一种角色(Role),表示在这个 Node 上包含着管理集群的一些必要组件。
Node 是工作节点 (worker Node)
K8s 系统是一套专注容器应用管理的集群系统,它的组件一般按功能分别部署在主控节点(master node)和计算节点(agent node)。对于主控节点,主要包含有 etcd 集群,controller manager 组件,scheduler 组件,api-server 组件。对于计算节点,主要包含 Pod、Service、ConfigMap、Volume、kubelet-proxy 组件。
容器的引入让原来主机仅可以部署 3-4 个进程的系统,现在可以充分利用容器进程隔离的技术在主机上部署 20-40 个进程系统,并且各自还不受影响。这就是容器应用的最大好处。
Kubernetes 是用于自动部署,扩展和管理容器化应用程序的开源系统,一般被 DevOps 团队用来解决在 CI/CD(也就是持续集成、持续发布)场景下遇到的工具链没法统一,构建过程没法标准化等痛点。
文稿:
Good morning , everyone , today , I’ll introduce Container Orchestration Technology–Kubernetes to you.
And It contains the following 4 parts.
So, in this part I’m going to explain what is Kubernetes .
Firstly, what problems does Kubernetes solve?
As is shown in the picture, From Traditional development to Container development , we can create multiple apps with only one operating system, and each apps has strong isolation with the others.
so , here comes the Kubernetes, it is an open source framework Which was original developed by Google.
It helps we manage applications that are made up of hundreds of containers in different environments.
In the second part , I wanna give you an overview of k8s .And what is the role of each of those components.
In this picture, we can see that , we use KubeCTL to communicate with K8s server , which is also called Matser. and each master has many nodes.
In this part , I’ll show you the details of each node
And here is a node. In this node , we have two pods ,one is called my-app , the second is database.
So pod is the smallest unit of Kubernetes ,and it is basically an abstraction over a container.
Pod is usually meant to run One application container inside of it, and we can run multiple containers inside of it . But usually it’s just one.
So now let’s see how these two pods communicate with each other.
each pod gets its own IP address.so, they communicate with each other using that IP address, which is internal.
However , In k8s , pod can die very easily.And when that happens for example, if I lose a database container because the application crashed or because the nodes.
K8s will create a new one in its place.
but the problem is , it will get assigned a new IP address, which obviously is inconvenient because we have to adjust it every time the pod restarts.
And because of that , another component of Kubernetes called service is used.
So service is basically a static IP address or permanent IP address that can be attached.
So it is to say , to each pod , such as my-app, will have its own service and database pod will have its own service too.
And the good thing is that the life cycles of service and the pod are not connected.
so even if the pod dies . The service and its IP address will stay, so we don’t have to adjust it.
Kubernetes has a component called configmap.what it does is it’s basically import our external configuration to application.
A configmap usually contains configuration data, like URLs of database or some other services .
So if we change the name of the service.The endpoint of the service, we just adjust the config map and that’s all.
We don’t have to build a new image and have to go through this whole deploy part.
And external configuration can also be database username and password , which is not secure in a plain text format , even though it’s an external configuration.
so for this purpose. Kubernetes has another component called secret.
Partly different from config map. secret is just used to store secret data credentials.
now let’s see another very important concept in K8s
As the database died or the pod gets restarted.The data would be gone and that’s problem and inconvenient.
Because we want our database data or log data to be persisted in a long term.
K8s provides volumns.
And how it works is that it basically attaches a physical storage on a hard drive to your pot and that storage could be on a local machine , a remote storage, or a cloud storage
Once the database pod gets restarted , all the data will be there persisted.
After introduce components, we’re gonna talk about basic architecture of Kubernetes.
As is shown in the picture , the Master is designed to schedule/re-start/re-schedule a pod, or monitor a node.
These are 4 processes that run on every masternode that control the cluster state and the worker nodes as well.
So the first service is API server, when we wanna deploy a new application and accommodate this cluster.
We have to talk to the API server on the master node
and the API server will validate our request and if everything is fine.
Then it will forward our request to other processes in order to schedule the pod.
it act as gatekeeper for authentication.
scheduler is another crucial component, when we send a request to schedule a new pod ,
Scheduler just decides on which NODE new pod should be schedules based on how much cpu\how much ram it need.
As for cotroller manager , what it does is to detect state changes like crashing of pods
So when pods die or reschedule. it makes a request for the scheduler to reschedule those dead parts
Finally, I’ll introduce ETCD for you,which is a key-value store of a cluster state. It is the brain of the cluster.
problems like What resources are available ? Did the cluster state change ? Is the cluster healthy ? are stored in ETCD
In summary.