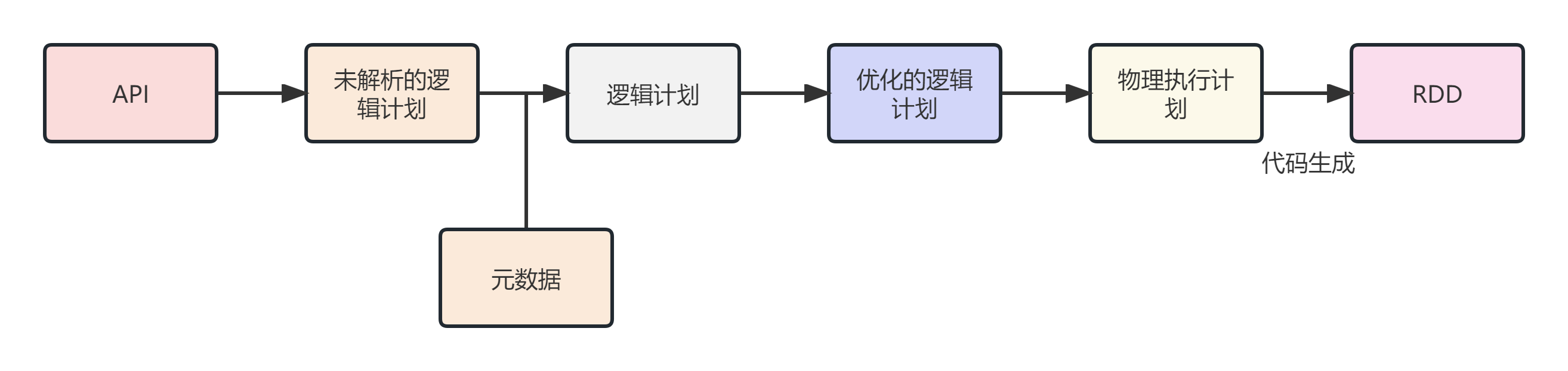
Spark SQL 的执行流程:
1 | 1.提交SparkSQL代码 |
Spark SQL 自带的优化器 Catalyst:
Spark SQL 优化器的核心执行策略分为两种:基于规则优化(RBO)以及基于代价优化(CBO)。
基于规则优化是一种经验式的、启发式的优化思路,主要依赖于过往所总结出来的优化规则,简单易行且能覆盖到大多数优化逻辑。例如,对两表进行join,是使用BroadcastHashJoin还是SortMergeJoin?在基于规则优化场景下,将通过手工设定参数来确定:如果一个表的数据量小于特定值,则使用BroadcastHashJoin。无疑,面对复杂的 join 操作, 这种方法显得很不灵活,而且力不从心。
基于代价优化就是为了解决这类问题,它会针对每个join,评估当前两张表在使用不同join策略下的代价,根据代价估算出最优策略。在Spark中,这些优化都是通过Catalyst实现的。
Catalyst优化器流程
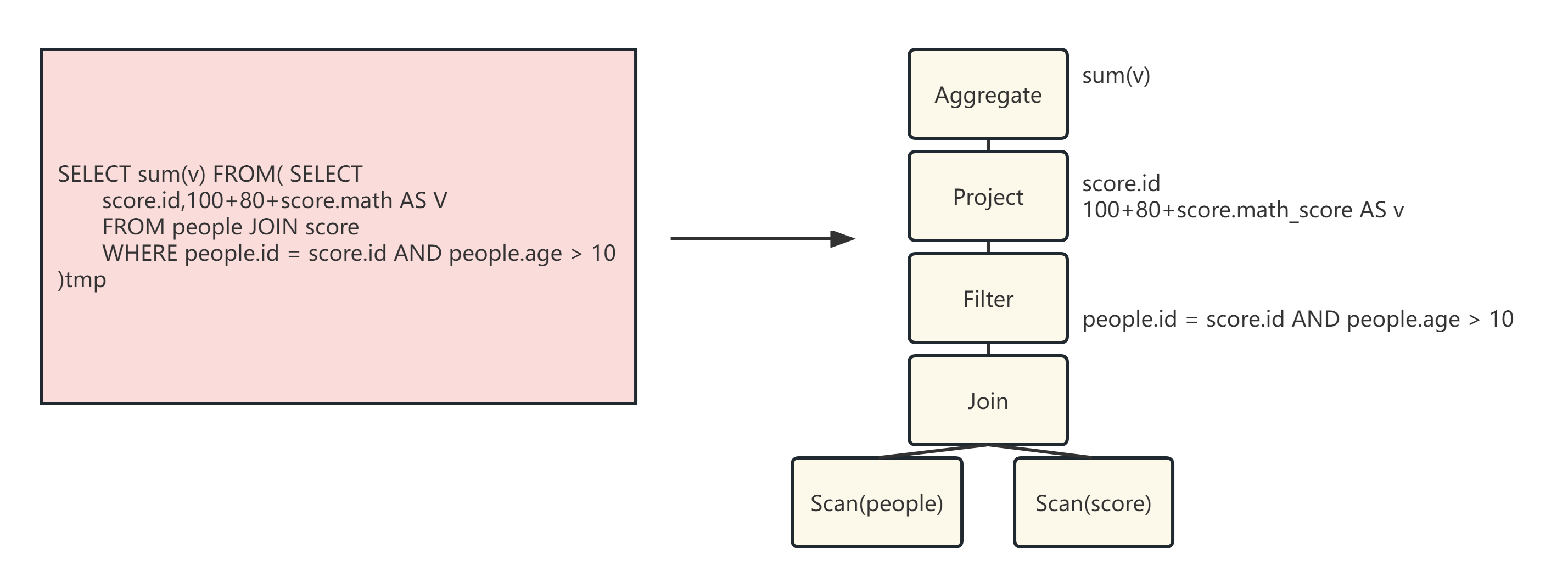
Step 1:解析SQL,并且生成AST(抽象语法树,如下图,从下往上读)
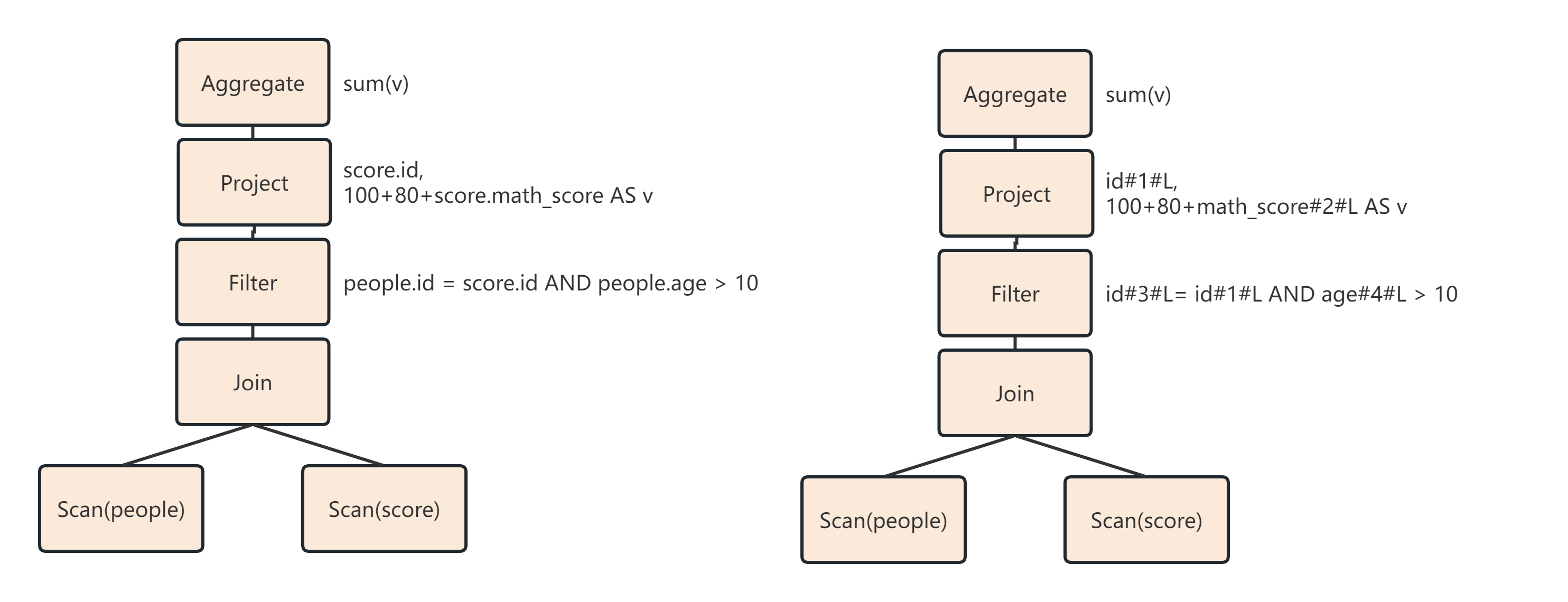
Step2:在AST中加入元数据信息,做这一步主要是为了一些优化,如下图
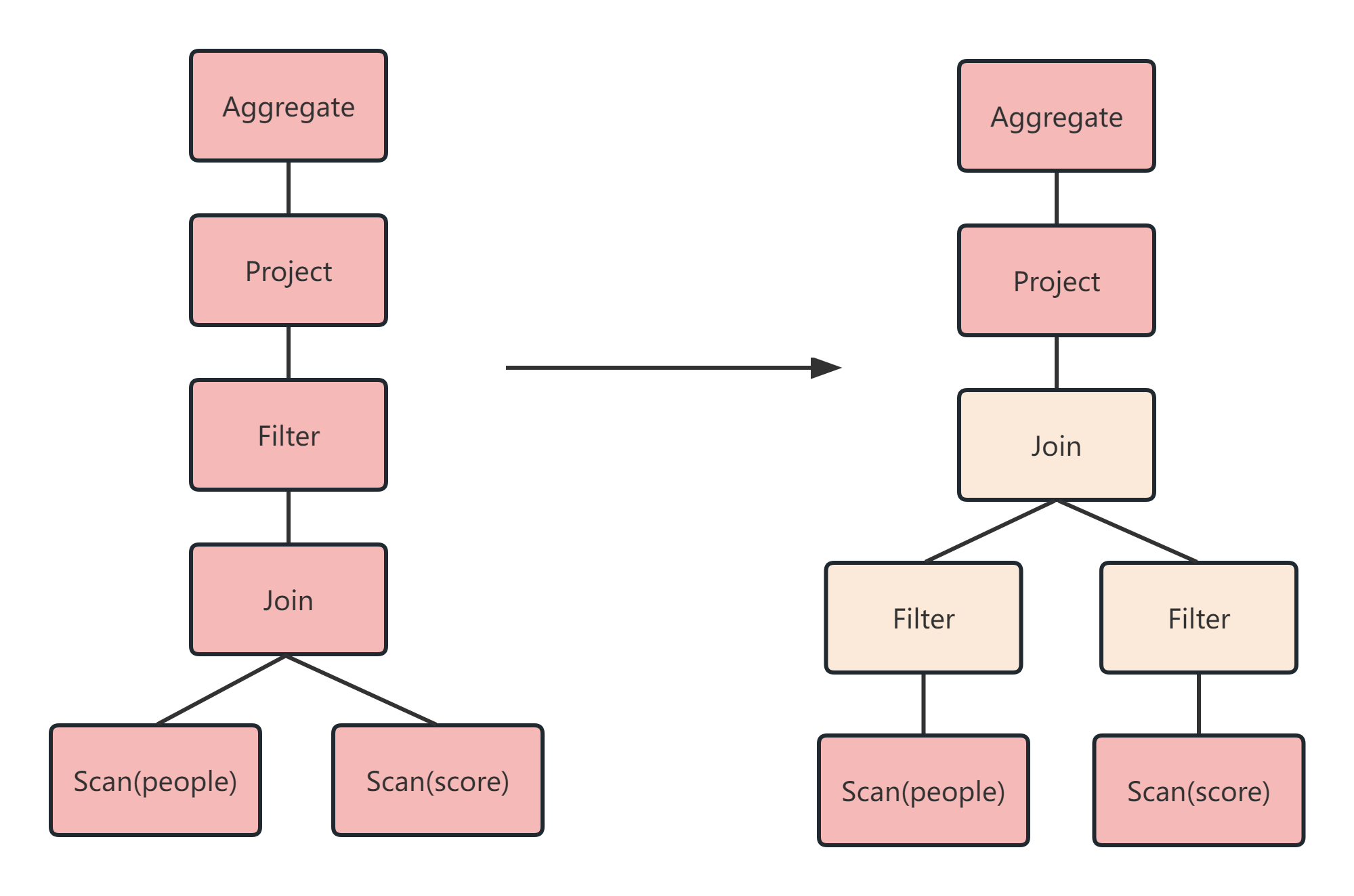
Step3:对已经加入元数据的AST,输入优化器,继续优化,从两种常见的优化开始。
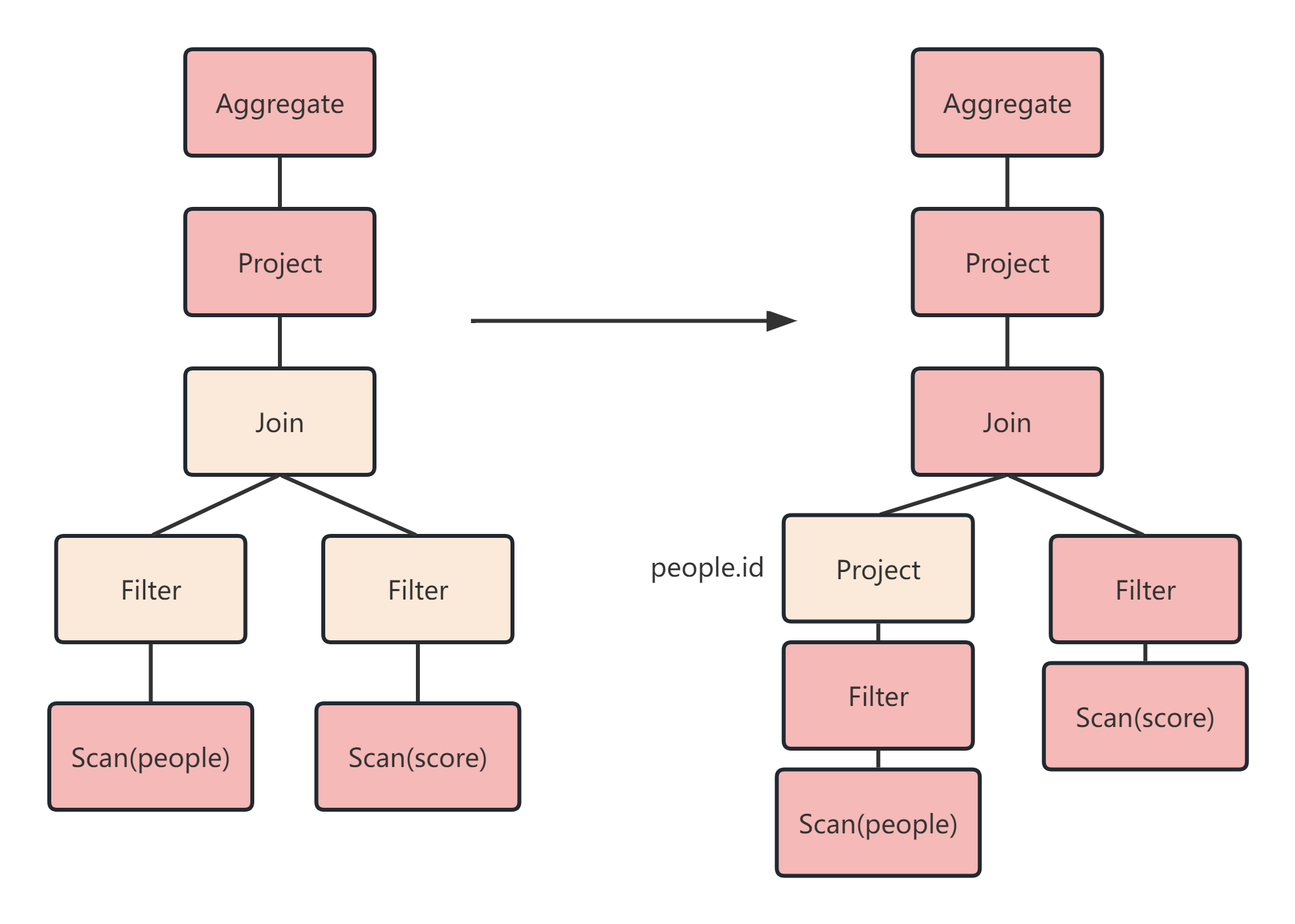
①断言下推(Predicate Pushdown):将filter这种可以减少数据集的操作下推,放在Scan的位置,这样就可以减少操作时候的数据量。
如下图:正常流程是先Join,然后做WHERE,断言下推后,会先过滤age,然后再Join,减少Join的数据量提高性能。
②列值裁剪(Column Pruning):在断言下推后执行裁剪。
如下图:由于people表之上的操作只用到了id列,所有可以把其他列裁剪掉,这样就可以减少处理的数据量,从而优化处理速度。
还有其余许多优化点,大概一共有一两百种,随着Spark SQL发展也会越来越多,想要了解更多可以查阅Spark源码:org.apache.spark.sql.catalyst.optimizer.Optimizer
Catalyst优化器总结
catalyst的各种优化细节非常多,大方面的优化点有2个:
①谓词下推(Predicate Pushdown)\断言下推:将逻辑判断提前到前面,以减少shuffle阶段的数据量。简述,行过滤,提前执行where。
②列值裁剪(Column Pruning):将加载的列进行裁剪,尽量减少被处理数据的宽度。简述,列过滤,提前规划select的字段数量。
Step4:经过上述流程后,产生的AST其实最终还没有办法直接运行,这个AST叫做逻辑计划,结束后,需要生成物理计划,从而生成RDD来运行。
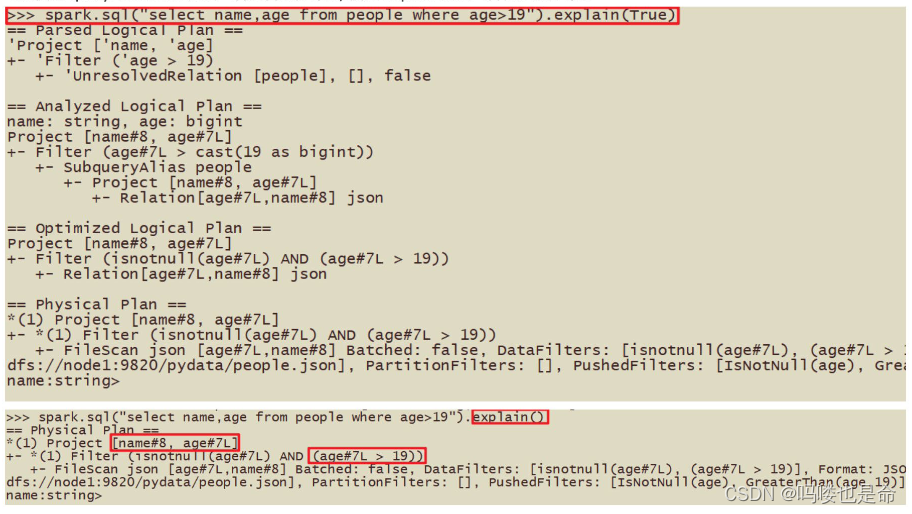
在生成“ 物理计划 ”的时候,会经过“ 成本模型 ”对整棵树再次执行优化,选择一个更好的计划,在生成“ 物理计划 ”以后,因为考虑到性能,所有会使用代码生成,在机器中运行。可以使用queryExecution 方法查看逻辑执行计划,使用explain方法查看物理执行计划。
用于Join优化的数据结构
BloomFilter: https://juejin.cn/post/7293786247655129129?utm_source=gold_browser_extension
不要求精准的话, 直接HyperLogLog就好了,12k内存 几乎可以忽略不计
**BitMap **
RoaringBitMap
HyperLogLog :https://www.yuque.com/abser/blog/mrv5ke
数据倾斜 :